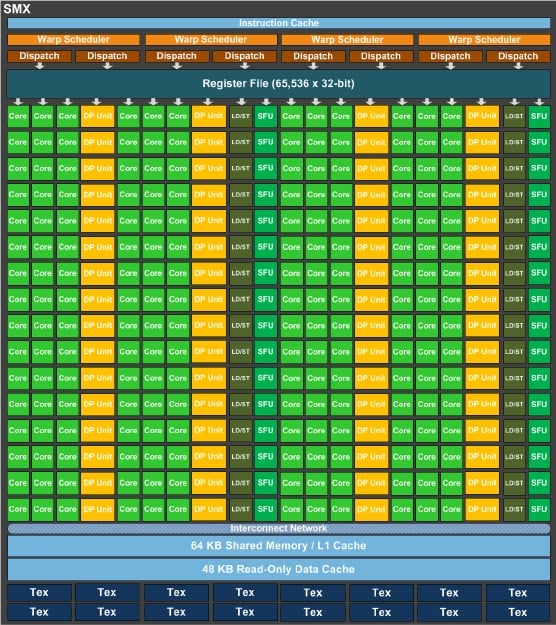
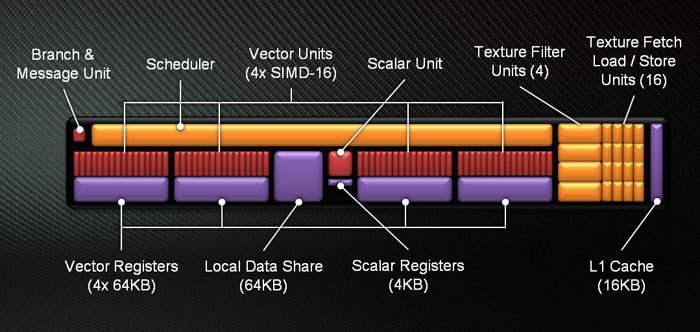
The initial AMD driver for OpenCL 2.0 has already been released. The latest version of the OpenCL parallel programming API is quite interesting as it supports shared virtual memory, dynamic parallelism, pipes and other features. Among the rest of them are the workgroup and sub-workgroup functions which are abstractions that on one hand simplify parallel primitive operations such as broadcast, scan and reduction operations and provide the opportunity for the compiler for further optimizations on the other.
In order to evaluate the workgroup function performance I developed a test case experiment for a reduction of the sum 1+2+3+...+N. Reduction is implemented in 3 different ways with 3 kernels. The first kernel is performed in the classical manner with shared memory. The last performs the reduction with the workgroup reduction function. The intermediate kernel uses shared memory for the inter-wavefront stages and the subgroup reduction operation for the intra-wavefront stage.
The results seem somehow disappointing. The execution configuration is a 64bit Linux system, with an R7-260X GPU. The results are as follows:
Workgroup and sub-workgroup OpenCL 2.0 function evaluation test case Platform/Device selection Total platforms: 1 AMD Accelerated Parallel Processing 1. Bonaire/Advanced Micro Devices, Inc. 2. Intel(R) Pentium(R) 4 CPU 3.06GHz/GenuineIntel Select device index: Device info Platform: AMD Accelerated Parallel Processing Device: Bonaire Driver version: 1642.5 (VM) OpenCL version: OpenCL 2.0 AMD-APP (1642.5) Great! OpenCL 2.0 is supported :) Building kernel with options "-cl-std=CL2.0 -cl-uniform-work-group-size -DK3 -DK2 -DWAVEFRONT_SIZE=64" 1. Shared memory only kernel Executing...Done! Output: 2147450880 / Time: 0.089481 msecs (0.732401 billion elements/second) PASSED! 2. Hybrid kernel via subgroup functions Executing...Done! Output: 2147450880 / Time: 0.215851 msecs (0.303617 billion elements/second) Relative speed-up to kernel 1: 0.41455 PASSED! 3. Workgroup function kernel Executing...Done! Output: 2147450880 / Time: 0.475408 msecs (0.137852 billion elements/second) Relative speed-up to kernel 1: 0.188219 PASSED!
The kernel with the workgroup function seems to perform more than 5 times slower than using just shared memory. This should definitely not be the case in a performance oriented environment like OpenCL. The performance of workgroup functions should be at least the same as using shared memory. Otherwise the workgroup functions are not essentially useful.
Unfortunately, CodeXL version 1.6 does not support static analysing of OpenCL 2.0 kernels and therefore I cannot inspect the resulting assembly code produced for the workgroup functions. According to theory swizzle operations has to be leveraged in order to optimize such operations.
Test case download link on github:
https://github.com/ekondis/cl2-reduce-bench
In case you notice any different results please let me know.
In case you notice any different results please let me know.